
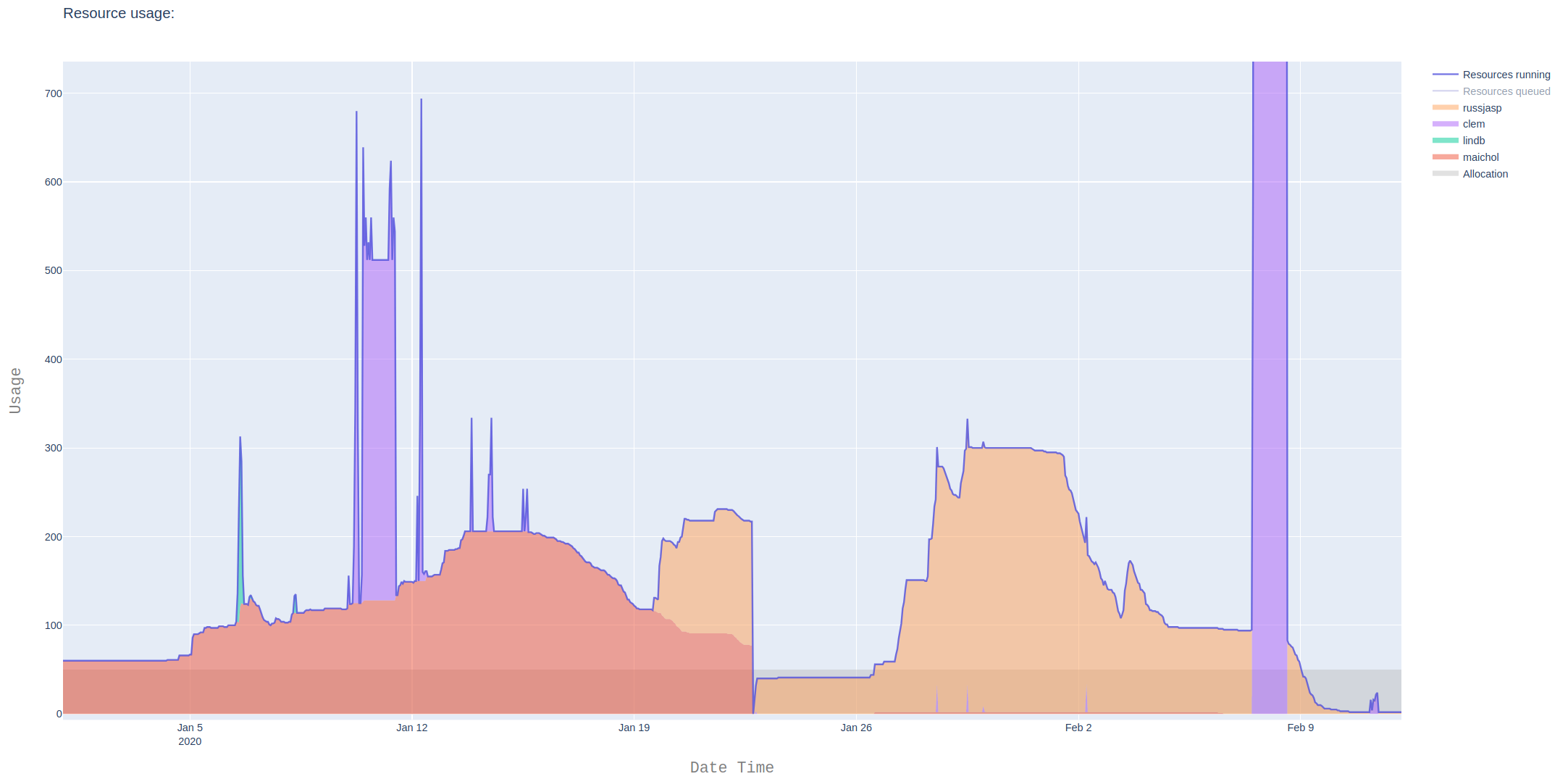
The majority of production work on the Compute Canada systems like Graham are dispatched to the compute nodes via the Slurm scheduler. The Compute Canada General Purpose (GP) systems (Beluga, Cedar, and Graham) are heterogeneous in that they have various node types with hardware options ranging in core count, memory availability, and GPUs, not to mention several model generations. The systems were also designed to accommodate a highly varied workload structures from the Canadian academic research community, including various job run times, CPU, GPU and memory sizes, as well as interactive workloads. The Slurm scheduler configuration is designed to maximize fairness, responsiveness and overall utilization. Beyond understanding how to request the appropriate resources required for a job, an understanding of the system specific configurations can have significant impact on the time to result on these systems by minimizing wait times in the queue. After covering job submission techniques this course provides information about monitoring jobs.
- Teacher: James Desjardins